検索・分析
|
|
|
検索・分析 |
|
機能408 |
Webページ熟語抽出 |
|
|
Webページで多く使用されている熟語を調べたい! |

|
|||

|
Webページで使用されている漢字熟語、カタカナ用語、英単語を抽出し、その出現頻度を集計します。 | ||
|
|
|||

|
朝日、読売、日経のWebサイトのトップページを調べて、使用されている熟語を調べる
|
■ トップページの熟語を抽出
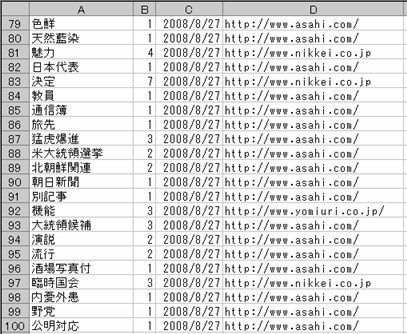
機能を実行すると、抽出結果が次のような形式でシートに記入されます。 |
|
| 列 |
内 容 |
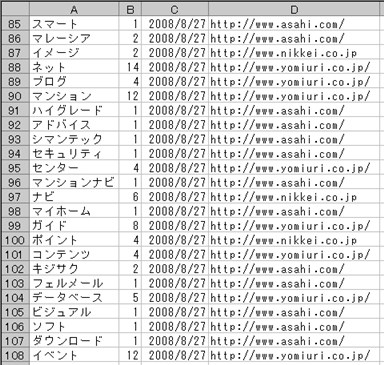
| A | 抽出された漢字熟語が記入されます。 |
| B | 熟語の出現頻度が記入されます。 |
| C | 熟語が抽出された年月日が記入されます。 |
| D | 熟語が抽出されたサイトのURLが記入されます。 |
 列C、D は、抽出の度に更新され、最新の抽出年月日とURLが記入されます。 列C、D は、抽出の度に更新され、最新の抽出年月日とURLが記入されます。 |
  任意のシートに熟語を抽出するサイトのURLを記入します。
任意のシートに熟語を抽出するサイトのURLを記入します。■ URLの記入
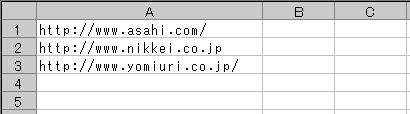 URLは列Aの1行目から連続して記入します。
URLは列Aの1行目から連続して記入します。 機能メニューで抽出する熟語の種別を指定します。
機能メニューで抽出する熟語の種別を指定します。■ 抽出する熟語の種別指定
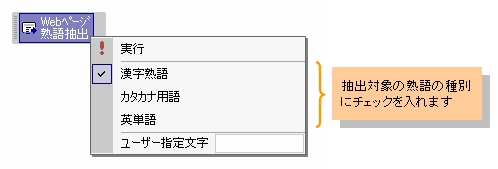 |
|||
|
|
サイトのURLを記入したシート(
)をアクティブにしてから、機能メニュー の[実行]をクリックして機能を実行します。 |
||
|
■ 機能の実行
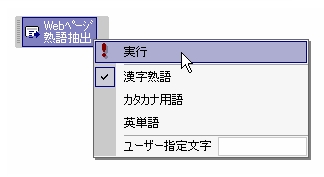  サイトが順次調べられ、熟語が抽出されます。
サイトが順次調べられ、熟語が抽出されます。■ 抽出結果の例(カタカナ用語)
 |
|||
|
|
集計結果の記録のため自動挿入されるシートは以下のとおりです。 | ||
| 熟語種別 | シ ー ト 名 | ||
| 漢字熟語 | FF漢字熟語リスト | ||
| カタカナ用語 | FFカタカナ用語リスト | ||
| 英単語 | FF英単語リスト | ||
|
|
ユーザー指定文字について | ||
|
この機能では、同一文字種が2文字以上連続している場合に「熟語」と判断します。スペース、改行、記号、数字などの文字は区切り文字として扱われ、熟語や単語を分割します。 英単語の場合は、アルファベットの大文字、小文字以外は原則的に区切り文字となりますが、機能メニューの「ユーザー指定文字」に区切り文字として除外する文字を指定することができます。これにより、@ やピリオドで区切られたメールアドレスや、:// で区切られたサイトURLなどを英単語として抽出することができます。 たとえば、次のようなサイトURLの場合、 http://www.freeformat.co.jp/AddInIndex.htm 通常は、http、www、freeformat、co、jp、AddInIndex、htm の7つの単語が抽出されます。サイトURLを1つの単語として抽出する場合は、ユーザー指定文字として、コロン(:)、スラッシュ(/)、ピリオド(.)を指定することにより、これらの文字で分割されること無く、ひとつの単語として抽出することができるようになります。 ■ ユーザー指定文字の設定例
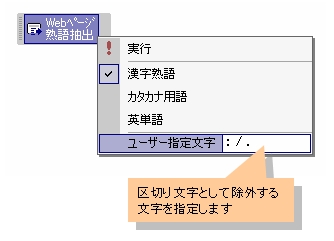 ユーザー指定文字を複数指定する場合は、それぞれを半角スペースで区切ります。
ユーザー指定文字を複数指定する場合は、それぞれを半角スペースで区切ります。 |
|||
 類似機能 類似機能 |
 機能368:熟語抽出 機能368:熟語抽出 |
|
機能372:カタカナ用語抽出 |
|
機能376:英単語抽出 |
|
機能697:単語リスト作成 |
| 関連機能 |
|
機能416:国語辞書一括検索 |
この機能のトップに戻る  |
2008.08.27/2017.03.16/2017.06.12 |